


- Index
- Technologies
- Big Data
Big Data
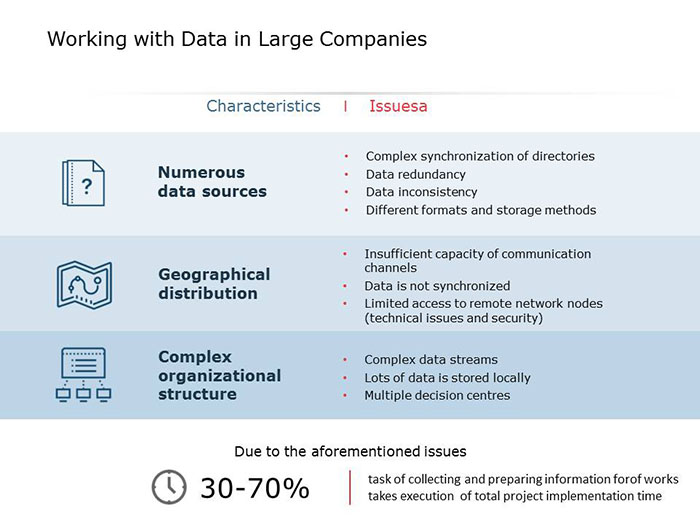
One of the main obstacles of data processing in large companies is large-scale distribution, both geographical and organizational. Each company has 20 to 50 information systems or file resources, in which inconsistent data in arbitrary formats is stored. Thus, the average user is forced either to view these data segments on an individual basis and consequently spend a considerable amount of time doing so, or they are obliged to settle for data that can be aggregated and located the fastest, often at the expense of information quality.
Previously, the basic approach for creating a single access point was the formation of a super-repository, with all the data converted into its formats, and everything that did not fit the format lost as a result. And this is not taking into account the costs of creating and maintaining the appropriate infrastructure.
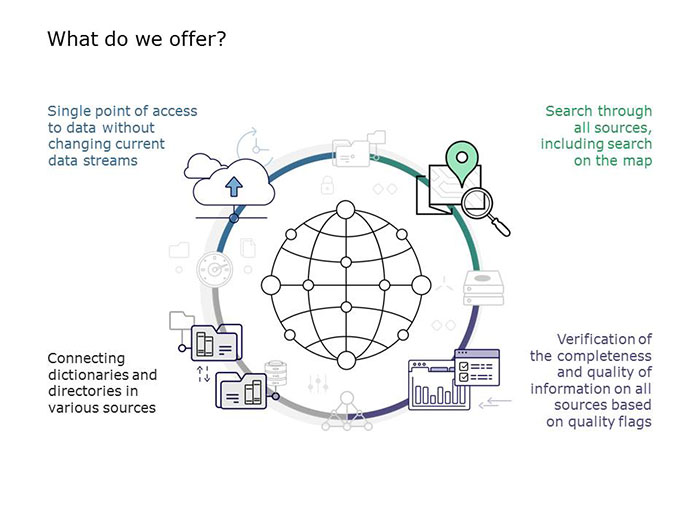
ITPS offers a different approach to the problem, based on the use of search services, similar to Internet search engines. The data itself remains where it is, and only meta-data is collected. At the same time, the business processes that have been developed in the companies are not changed, meaning the data cannot be lost. A user can view all the data in a single window, and in order to obtain more detailed information they can go to the source system.

The architecture of the solution allows for practically unlimited system scaling, and the open code is used for its customization to suit the needs of a particular company by its own developers, without having to be reliant on further vendor services.
A developed search interface allows for three types of search query to be performed: spatial (with the use of GIS interface), attributive, including the links by logical operators, and contextual. In this case, the search query combination can be arbitrary.
In addition to creating a single point of access to data, the platform allows a global system for checking data completeness and quality to be developed, based on the normalization of intersystem directories and creating rules for data control as well as expert setup of quality flags. Thus, the end user can get the most relevant data without any extra work.
The developed solution has already been proven in practice and received an award at the Global CIO contest for the "Best project for managing large-scale digital production data" nomination.
This website uses cookies. By continuing to browse, you consent to our use of cookies.